使用nodejs爬取图片
在运行代码前,请确保本机是否有nodejs环境
D:\ > node -v
v12.1.0 //版本号- 需要用到的包
axios //请求页面
cheerio // 把get请求的页面 可以使用jq的方法来获取dom
fs // 文件读写模块
request // 请求模块 用来请求下载地址
path // 路径模块
url // 路由模块- 爬虫遵循的规则
遵守 Robots 协议,谨慎爬取
限制你的爬虫行为,禁止近乎 DDOS 的请求频率,一旦造成服务器瘫痪,约等于网络攻击
对于明显反爬,或者正常情况不能到达的页面不能强行突破,否则是 Hacker 行为
如果爬取到别人的隐私,立即删除,降低进局子的概率。另外要控制自己的欲望
- 本次案例百度图片表情包
js
const axios = require("axios")
const cheerio = require("cheerio")
const fs = require('fs');
const request = require("request");
const path = require('path');
const url = require("url")
/**
* 休眠方法,因为一次访问太多次目标网址会被拉黑
* @param {Number} time 休眠时间以毫秒为单位
* @returns Promise
*/
const sleep = time => {
return new Promise(function (resolve, reject) {
setTimeout(function () {
resolve();
}, time);
})
}
/**
* 爬取某个地址下的img 图片
* @param {String} httpUrl 目标地址
* @param {Boolean} isBaidu 是否为百度图片地址
*/
async function start(httpUrl, isBaidu) {
// 获取目标网址的dom节点,使用jq的方法来获取dom节点
const { data } = await axios.get(httpUrl)
let img = [];
// 针对百度 进行爬取数据
if (isBaidu) {
img = getBaiDuImg(data)
} else {
const $ = cheerio.load(data)
// 根据dom获取img src
$(".imgbox img").each(function () {
let src = dealImgUrl($(this).attr("src"), httpUrl)
img.push(src)
})
}
// 检测当前文件夹是否存在存储图片的文件夹
const random = parseInt(Math.random() * 100)
const dirPath = "./img" + random
if (!fs.existsSync(dirPath)) {
fs.mkdirSync(dirPath)
}
fs.writeFileSync("./data.json", JSON.stringify(img), "utf-8")
/**
* 在这里为什么不使用forEach遍历? 答案在下方链接
* https://blog.csdn.net/yumikobu/article/details/84639025
*/
for (let i = 0; i < img.length; i++) {
const item = img[i]
await sleep(1500)
console.log(item + "开始下载");
// const extname = path.extname(item) || '.jpg'
// const filename = (i + 1) + extname
let myUrl = new URL(item) // node vision must v10 up!
let httpUrl = myUrl.origin + myUrl.pathname
let filename = i + path.basename(httpUrl)
const write = fs.createWriteStream(dirPath + "/" + filename)
request.get(item).on('error', function (err) {
console.log(item + "下载失败", err);
}).pipe(write)
console.log(item + "本地下载结束");
}
}
process.on("exit", () => {
console.log("爬取结束");
})
/**
* 处理img的src
* @param {String} src 路径
* @param {String} pathurl url地址
* @returns 返回图片链接地址
*/
function dealImgUrl(src, pathurl) {
if (src.substr(0, 8) === 'https://' || src.substr(0, 7) === 'http://' || src.substr(0, 2) === "//" || src.substr(0, 5) === "data:") {
return src
}
return url.resolve(pathurl, src)
}
/**
*
* @param {String} str 百度返回的html字符
* @returns {Array} 返回图片链接地址
*/
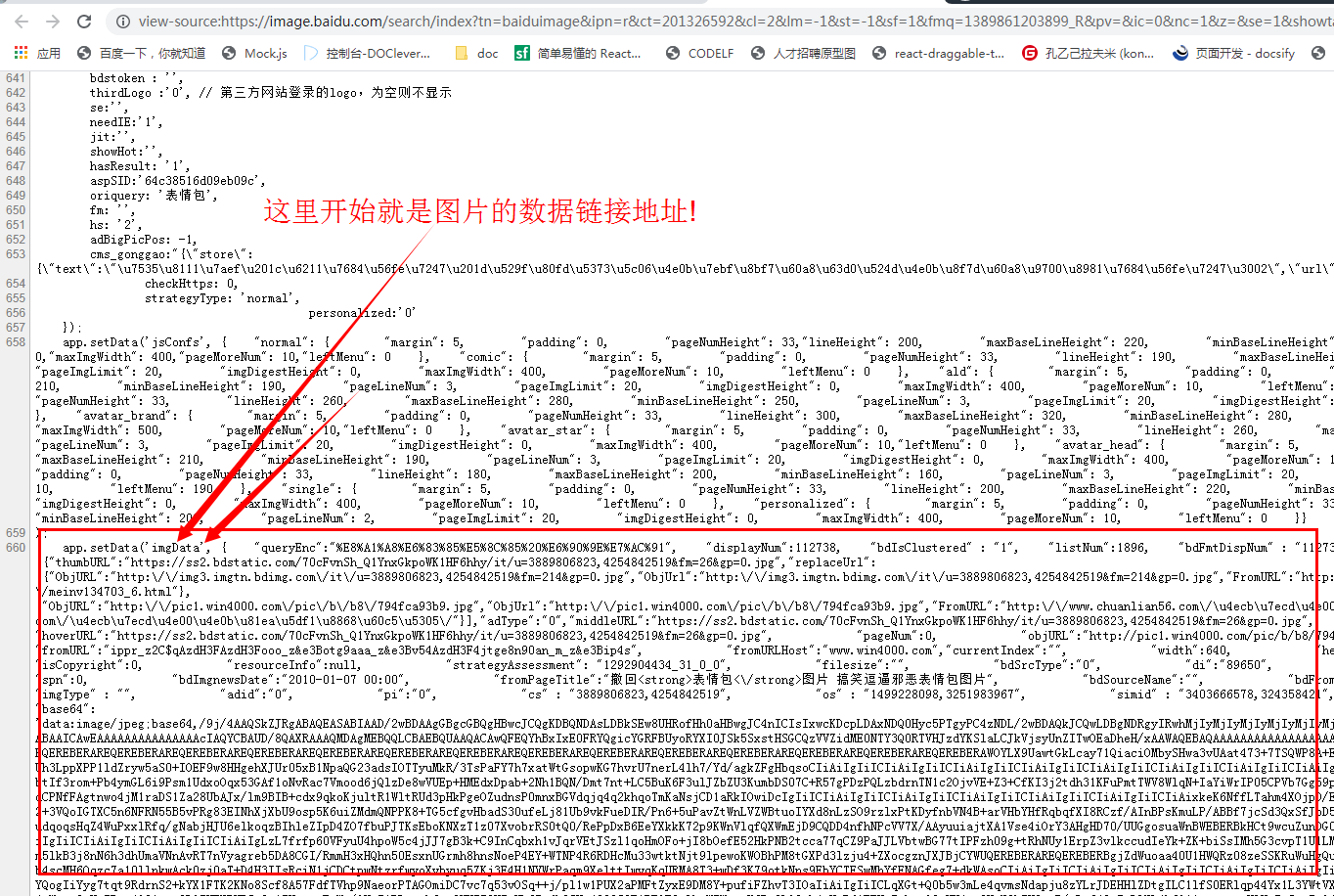
function getBaiDuImg(str) {
var reg = /app\.setData\(\'imgData\'\,\s+\{(.*?)\"data\":(.*?)\]\}/g
var result = reg.exec(str)[2] + ']'
result = result.replace(/\'/g, '"')
result = JSON.parse(result)
const img = []
result.forEach(item => {
if (item.objURL) {
img.push(item.objURL)
}
})
return img
}
// const HTTPURL = "https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1605517415488_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&hs=2&sid=&word=%E7%94%B5%E8%84%91%E5%A3%81%E7%BA%B8++%E6%A2%85%E8%A5%BF"
const HTTPURL = "https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&sf=1&fmq=1389861203899_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ala=6&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&fr=ala&ala=1&alatpl=adress&pos=2&oriquery=%E8%A1%A8%E6%83%85%E5%8C%85&alaTag=0&&word=%E8%A1%A8%E6%83%85%E5%8C%85%20%E6%90%9E%E7%AC%91&hs=2&xthttps=111111"
// 调用start 函数 开始进行爬取
start(HTTPURL, true)仔细分析了一下,百度图片并不是在请求页面的时候就把图片的数据渲染到dom上了,而是通过js脚本创建出img的.所以使用正则匹配到img的数据,就可以知道图片链接地址了.